# Task 2
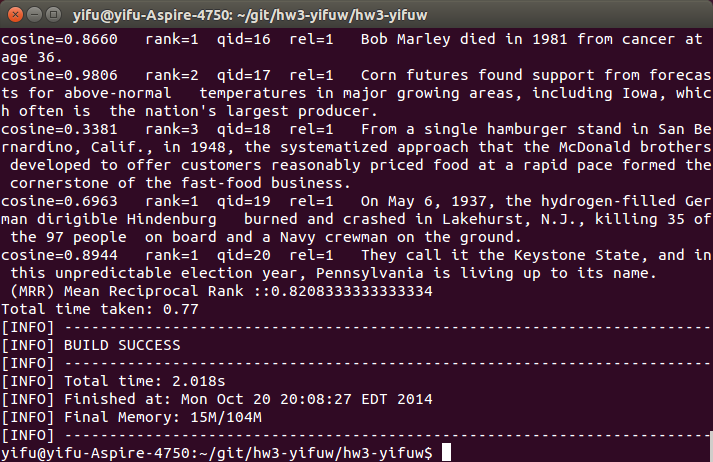
This is the origin result of task 1. Our goal is to improve MRR as much as we can.
Step 1. Optimalizing Tokenize Algorithm
The origin tokenize algorithm just split sentence by spaces. This method will get some wrong results like below:
world.
“Mendocino
Tree”
Lake?
Bernardino,
…
In this case, the word “world.” in answer text will not match word “world” in query text. But actually they should be considerd as same.
I updated this tokenize algorithm to reduce mismatch. Firstly, the sentence is converted to lower case and trimed. Then, I split words by many seperators rather than just blank using regular expression, which includes:
! ? , . “ ; () [] {} <>
|
|
Note there are still some exceptions:
- Comma: inside numbers like 3,000,000
- Period: Not for abbreviations: O.K. Not for URLs: www.google.com
- Slash: Not for fractions: 1/2. Not for URLS: www.google.com/search
- …
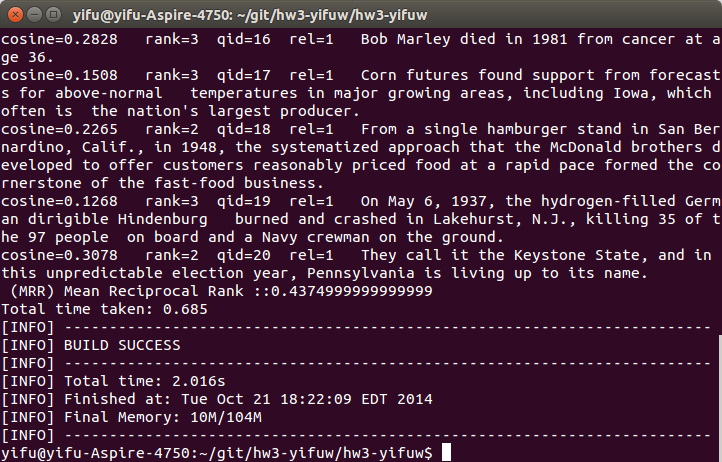
It is hard using regular expression to exclude all these exceptions. But by applying this method, the MMR score already has a signifiant improvment from 0.43 to 0.58. So I believe this approach maybe is good enough for this part. If we want our tokenize algorithm more precisely, we may need a dictionary of words, and some data structures like prefix tree and Trie.
Better Stemming Algorithm
In last part, we optimaized tokenize algorithm by applying multiple seperaters. However, there is still a problem: Our model can not distinguish different forms of same word. For example, it will treat “is”, “was” as different words. But actually these two words play the same role in sentence.
We can use provided Stanford lemmatizer to solve this. Just call the stemWord(str) function before we add tokens to list.
Here are some converted words:
named, name
leading, lead
is, be
feet, foot
mcdonald’s,mcdonald’
…
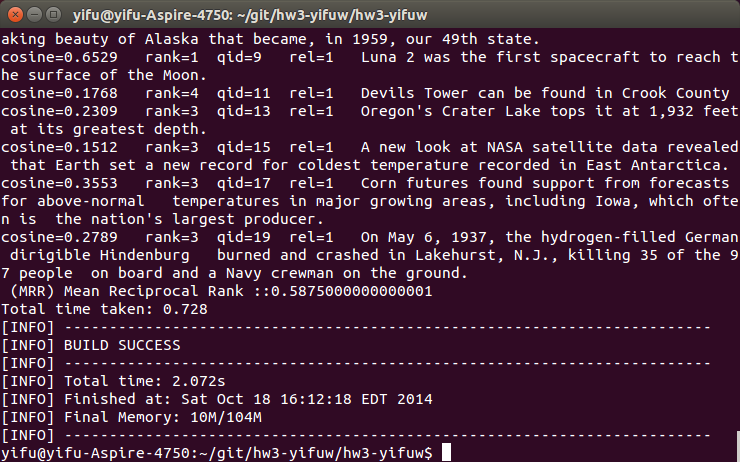
Last one seems not like a good conversion, so I modified a little to change “mcdonald’s” to “mcdonald”. This method improves MMR score from 0.58 to 0.70. Again, a remarkable progress.
Apply Some Different Similarity Measurement
I did not know there are so many ways to evaluate string similarity until this project.
Hamming distance:
“karolin” and “kathrin” is 3.
Levenshtein distance and Damerau–Levenshtein distance:
- “kitten” → “sitten” (substitution of “s” for “k”)
- “sittin” → “sitting“ (insertion of “g” at the end).
Soundex Distance Metric:
Mapping char to similar value if it sound alike: “Robert” and “Rupert” return the same string “R163” while “Rubin” yields “R150”.
Jaccord Coefficient:
Dice’s coefficient:
For two word night, nacht:
We would find the set of bigrams in each word:
{ni,ih,gh,ht}
{na,ac,ch,ht}
Each set has four elements, and the intersection of these two sets has only one element: ht.
Inserting these numbers into the formula. s = (2 · 1) / (4 + 4) = 0.25.
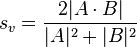
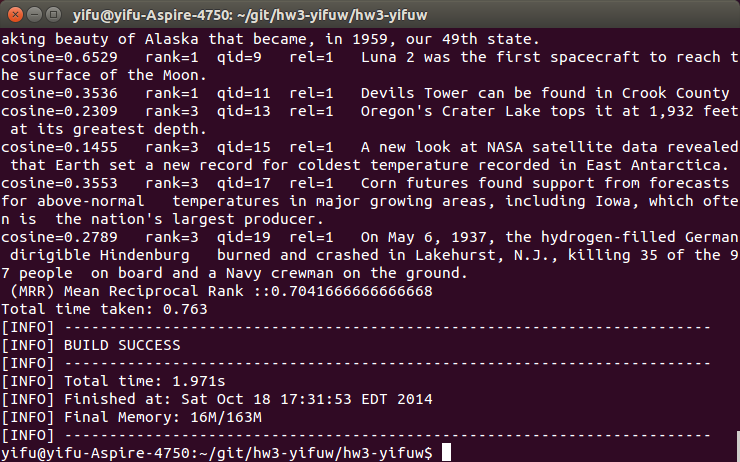
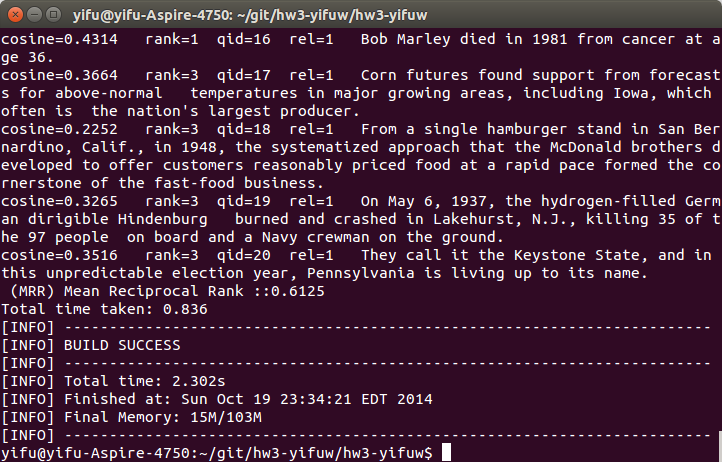
I firstly chose dice coefficient algorithm to calculate string similarity. However, from the result below, we can see that the MRR score reduces from 0.70 to 0.61. I had double checked the whole function, found nothing wrong. The probably reason is that optimized tokenlize algorithm and stemming algorithm helps cosine similiarly performs better than dice coefficient. So dice coefficient has nothing to do with last two steps’ optimization. This algorithm has a better performance than original cosine similiarly algorithm (MMR from 0.43 to 0.61).
As the result, although cosine similiarity algorithm is somehow naive, it does not break the structure of token, which means it has a potential to optimize. Like using Stanford Lemmatizer to put differnet forms of same word into one category. However, if we using dice coefficient, although it breaks word into a smaller “grain size”, it also loses information of words, thus we can not optimize the performance from the meaning of words. So if we just want to compare two documents’ similarity, we may want to choose dice coefficient. But if we want to learn more from the meaning of sentence, we should keep the structure of tokens.
Then, I usd Jaccord similarity. This method is easy to implement, just change a little from cosine similarity. We get pretty results from this method, MRR jumps from 0.70 to 0.82(see figure below). It is probably because this method is more precisely than cosine similarity, and it can benefit from other steps’ optimaztion, since it not break the structure of tokens.